
Video Segmentation: A Breakdown of How It Works and Its Advantages
If you’ve ever been curious about how surveillance systems, underwater documentaries, or live sports analysis can identify individuals, vehicles, or orcas using videos, the answer lies in video segmentation. Video segmentation is the process of dividing videos into different regions based on their characteristics, such as object boundaries, motion, color, texture, and other visual features. Its main purpose is to separate different objects from the background and provide a more detailed representation of the video’s content.
The Advantages of DEVA in Video Segmentation
Expanding the use of algorithms for video segmentation can be expensive because it requires labeling a significant amount of data. However, researchers have developed a decoupled video segmentation called DEVA, which simplifies object tracking without the need for extensive training data. DEVA consists of two main parts: one specialized for finding objects in individual frames and another for connecting the dots over time, regardless of the objects involved. This approach makes DEVA more flexible and adaptable to various video segmentation tasks.
Combining Simplified Models and Universal Temporal Propagation
This design allows for the use of a simpler image-level model for specific tasks, reducing the cost of training. Additionally, a universal temporal propagation model only needs to be trained once and can work for multiple tasks. To ensure smooth collaboration between these two modules, a bi-directional propagation approach is used. This approach merges segmentation guesses from different frames, resulting in consistent and real-time segmentation.
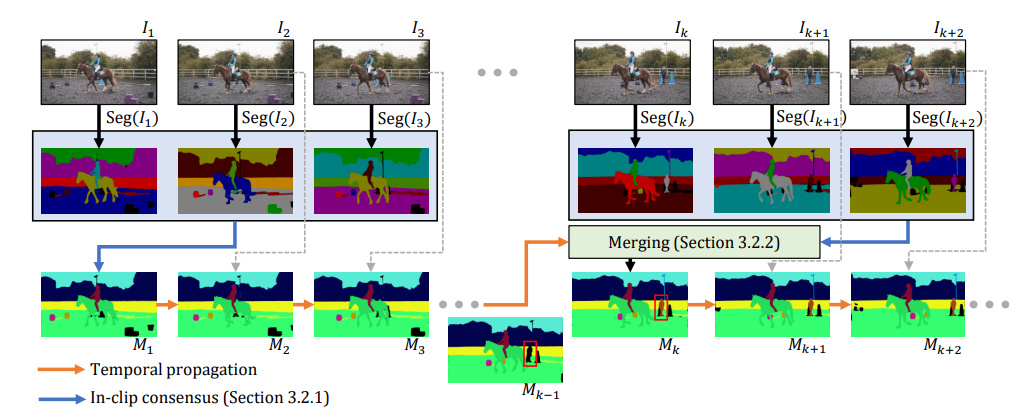
The image above provides an overview of the framework for DEVA. The research team filters image-level segmentations with in-clip consensus and temporally propagates the results. When a new image segmentation is introduced at a later time step, it is merged with the propagated results to ensure continuity in the segmentation.
Better Generalization Capabilities
This research significantly relies on external task-agnostic data, reducing the dependence on specific target tasks. As a result, it exhibits better generalization capabilities, especially for tasks with limited available data. Additionally, fine-tuning is not required. When combined with universal image segmentation models, this decoupled paradigm demonstrates cutting-edge performance in large-vocabulary video segmentation in an open-world context.
To learn more about this research, you can check out the paper, visit the Github repository, or explore the project page. All credit for this research goes to the dedicated team of researchers. Don’t forget to join our ML SubReddit with 30k+ members, our Facebook community with 40k+ members, our Discord channel, and subscribe to our email newsletter to stay updated with the latest AI research news and cool projects.
If you enjoy our work, you’ll love our newsletter. Subscribe now!