
Adaptive computation allows a machine learning system to modify its behavior according to the complexity of the input. Unlike traditional neural networks that utilize the same resources for every input, adaptive systems can expend more or less effort (measured in FLOPs) based on the task.
So, why is adaptive computation exciting? There are two main reasons. First, it can assist with challenging problems like arithmetic by allocating more steps for intricate tasks. Second, it enables professionals to fine-tune costs by regulating how much effort is exerted on new inputs.
In neural networks, adaptivity can be realized by employing different functions for various inputs or by modifying computation budgets. Research exists on both aspects, such as mixture-of-experts that allocate different parameters for distinct inputs, or dynamic computation budgets where the model determines how many layers to utilize.
The new model being introduced, named AdaTape, incorporates both these techniques. Being a Transformer model, it’s constructed on cutting-edge technology, but it also possesses a dynamic set of tokens to conform to each input’s complexity. Implementation is straightforward, efficiency is higher compared to similar models, and it exhibits superior performance on standard tasks while maintaining a solid equilibrium between quality and cost.
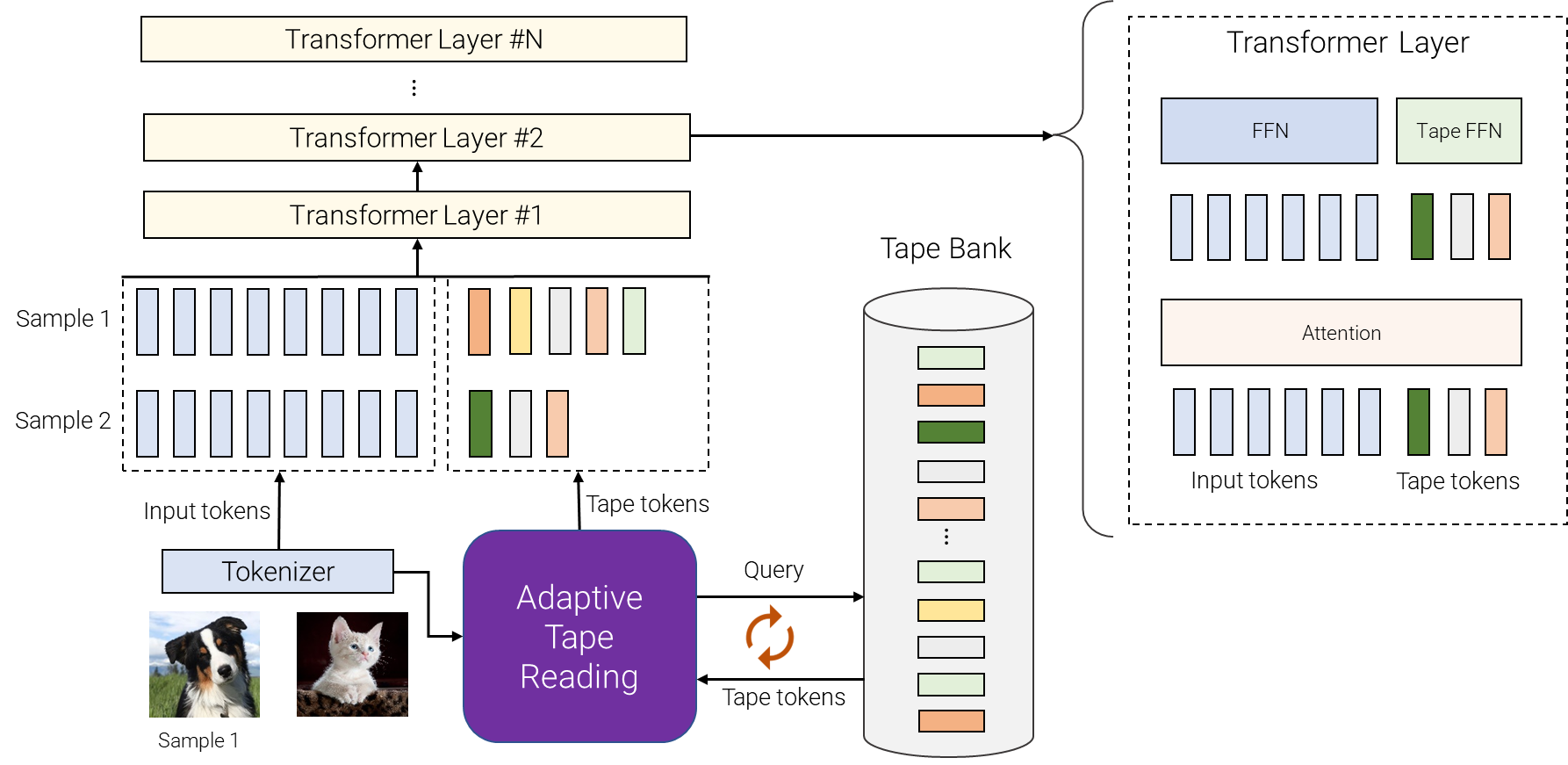
How does AdaTape function? It has a “tape bank” of tokens from which it can draw. Depending on the input, a different number of tokens can be selected. Two methods to create this bank are available: input-driven, where tokens are derived from the input itself, or a learnable bank, where tokens are trainable vectors. The learnable bank endows AdaTape with more adaptability to cater to each input.
Once the tokens are chosen, they are combined with the original input and processed through the Transformer layers. It has even been discovered that utilizing different feed-forward networks for the original input and the tape tokens enhances the quality slightly.
AdaTape introduces a helpful inductive bias in handling complex tasks. The standard Transformer struggles with the parity task, where it must determine the evenness or oddness of the number of 1s in a sequence. Surprisingly, this seemingly simple task is unsolvable by the standard Transformer, but AdaTape’s inductive biases make it possible to tackle this challenge.

The standard Transformer and Universal Transformers couldn’t do the parity task because they can’t maintain a counter within the model. AdaTape, however, can do this task better than all the rest. It has a unique feature that allows it to keep track of a counter, something regular Transformers can’t do.
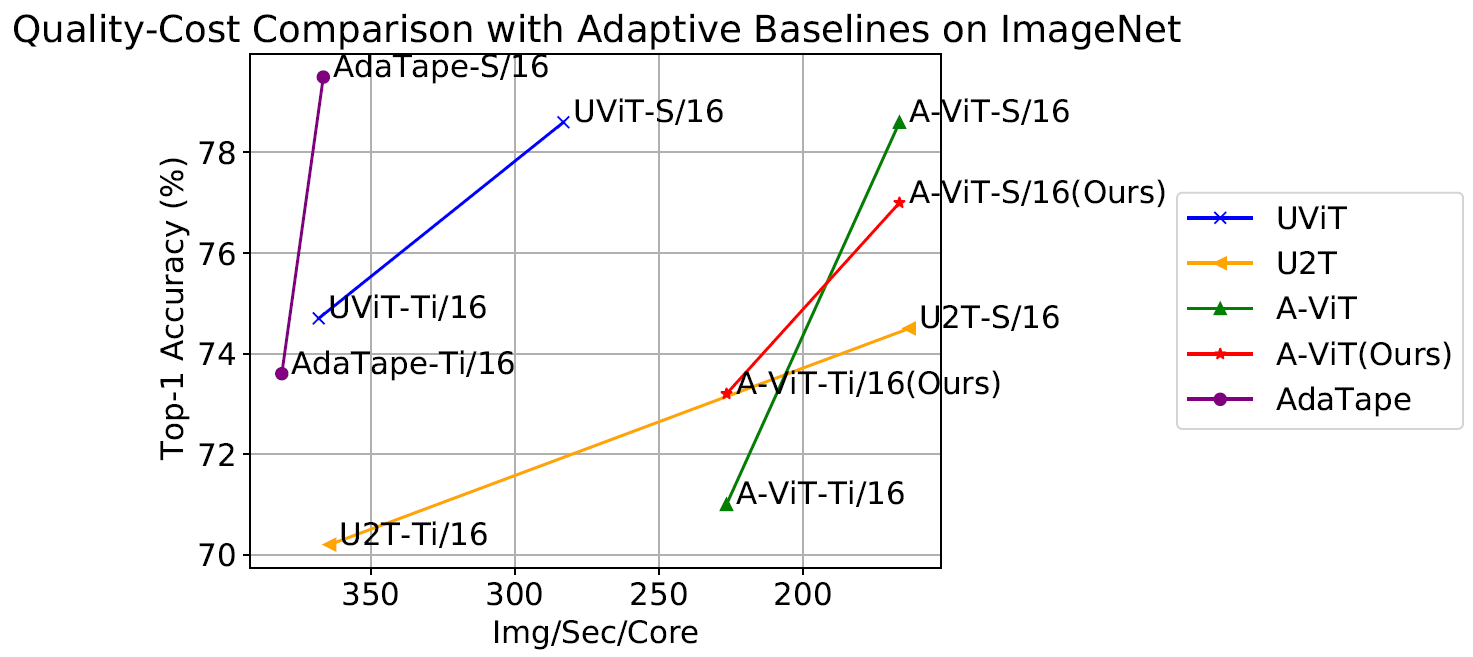
When tested on image classification, AdaTape was also impressive. It was trained on ImageNet-1K from scratch and outperformed other methods like A-ViT and Universal Transformer ViT (UViT and U2T) in both quality and speed. Larger AdaTape models even worked faster than smaller ones. This confirms earlier findings that adaptive model depth architectures might not be ideal for some accelerators, like the TPU.
A study of AdaTape’s behavior
In a study of AdaTape’s behavior on tasks like the parity task and ImageNet-1K, as well as the JFT-300M validation set, researchers found some interesting patterns. They used heatmaps to see how AdaTape selects tokens and found that it often picks the central patches. In pictures with natural images, the main object is usually in the middle, so these central patches tend to be more informative. This shows how smart AdaTape is, as it can focus on the most important parts of an image to improve its performance.

Conclusion
AdaTape is a new technology that uses elastic sequence lengths through an adaptive tape reading mechanism. Unlike standard and existing adaptive transformers, it introduces a unique bias, making it more capable of solving difficult tasks. Tests on image recognition show that AdaTape performs better than its counterparts while using the same amount of computation.